Ordered, immediately called back and the same day delivered the order.Very pleased with the work. Thank you for prompt and accurate work https://africarx.co.za/buy-levitra-south-africa.html great prices, delivered on the day of the order. Pleasant managers consult by phone.
Wordnet vs distributional determination of word similarity
Wordnet vs. Distributional determination of word similarity
PO Box 2100, Adelaide 5001, South Australia
Dongqiang.Yang | David.Powers@flinders.edu.au
Abstract. In this paper we propose a kind of distributional word similarity after extracting some syntactic relation in the sentence. As a supplement to the richness of WordNet, it acquires some lexical knowledge from large volume of corpus. It is also a powerful tool to judge word similarity. Introduction and Aims
The problem of how similar words are or how closely words are associated has important applications in several areas including automatic thesaurus construction (Grefenstette 1992; Hearst 1992; Riloff and Shepherd 1997; Pichon and Sébillot 1998; Berland and Charniak 1999; Caraballo 1999), word sense disambiguation (Dagan, Marcus et al. 1993; Lin 1997; Dominic 2003) and information retrieval (Salton 1973; Grefenstette 1992; Leacock, Towell et al. 1996).
Word Association Norms (refs) is a knowledge base available for word association
applications based on empirical results from Psychological word association experiments in which a subject is given a stimulus word and asked to respond with the first word that comes to mind. The data are provided in the form of lists of subject stimuli, responses and frequencies that can be interpreted as indicating the extent of the similarity between the paired words.
Word association data of a different kind can also be captured from corpora of
naturally occurring speech, or text, and may be further categorized according to topic, register, ethnicity, etc.
WordNet and Roget’s Thesaurus represent hand-crafted repositories of similar
information, although in some respects richer information is provided by these – e.g. WordNet in some cases identifies the kind of relationship between words.
We are particularly interested in how to automatically collect, update and make
effective use of WAN-like or WordNet-like data from large corpora.
2 Dongqiang Yang and David M. W. Powers Current approaches
The meaning of the word is to a large extent latent in the contexts where it occurs and most vocabulary is learned from context rather than a dictionary. Indeed lexicons, dictionaries and thesauri are just specialized contexts that are designed to facilitate catching the meaning of an unfamiliar word, but a mere gloss or definition is insufficient to fully convey the scope of such a word.
Each word may be regarded as interacting with and having a relationship with all
its neighboring words (Firth 1957), but these relationships and interactions can vary quite considerably and are directly dependent on the both the grammatical and conceptual systems of both the speaker and listener as well as the context in which they are uttered. For example, “David got a cold and had to go … ”, it is not difficult to infer that the omitted portion of the sentence should be related to going to the doctor or hospital or even home and bed. The missing content is likely to contain medical or pharmaceutical terms, but a raw unmotivated completion like “… to the shopping center” has too little an association with the cold to be likely (unless it was followed by something about doctors or medication). We can similarly guess aspects of the broad meaning of the word “eucalyptus”, even without any pre-knowledge in it, through co-occurrence words that have some kind of syntactic relation to in contextual sentences – in different contexts we might learn it means a kind of gum tree, food for koalas, an oil for removing stickers, or a medication for relieving colds.
Roughly speaking, two types of relations between the stimuli and the responses in
the WAN can be found: syntagmatic associations and paradigmatic associations. Syntagmatic association defines the relation between words in different slots in the sentence and implies the word co-occurrence in the syntactic structure of the sentence. Paradigmatic association represents the relationship between words that can occur in the slot in a sentence in both a syntactic and a semantic sense. To acquire these relationships in the corpus two kinds of techniques are relatively popular with respect to how to represent word meaning.
Manmade dictionary or thesaurus
Machine-readable dictionaries provide a well-designed pattern for inferring word
senses. Lesk (Lesk 1986) utilizes overlapping between definitions for each sense of stimulus and responded words, i.e. how many common words they share, to stands for the choices in cross sense-comparison of the words. (Pedersen, Banerjee et al. 2003) propose to judge the concepts similarity through their gloss vectors from the matrix that are build on the 1.4 million glossary corpus of WordNet. The cell in the matrix is the co-occurrence frequency in each concept gloss in WordNet. This method is a partial improvement of the Lesk algorithm (Lesk 1986), in which the similarity is reflected by the common words of glosses for two different word senses. Owing to the concise gloss of each sense and the slow and rare updating of WordNet, this method has little use in practice.
Another class of knowledge-rich method makes use of semantic networks, or a
semantically tagged corpus, to induce the relatedness between words by calculating semantic distance between two words in a the well-organized taxonomy such as WordNet or Roget’s thesaurus (Pedersen, Banerjee et al. 2003; Yang and Powers
Wordnet vs. Distributional determination of word similarity 3
2005) . Note that different hierarchies may relate only the same part of speech (WordNet) or may handle mixed parts of speech (Roget). In WordNet’s noun taxonomy it is primarily the hyper-hyponym and hol-meronym links that have been used to carefully categorize and distinguish the relationship between the different words and senses.
Knowledge-poor methods,
The frequency of co-occurrence in context can be represented using techniques
such as word contingency matrices or n-gram statistics with or without making use of information about or deriving from syntactic structure. Given unsupervised learning is used to acquire the semantic information about a word, it should in principle cover broader domains and larger vocabulary sizes than the retrieval of word similarity from dictionary or semantic networks. • a bag of words
Here we assume that semantically related words that are likely to co-occur in a
context (traditionally document) can be treated as an unstructured bag of words for the purposes of determining word associations/similarity. A matrix may be constructed in word-by-word or word-by-document order within fixed size window where any cell value could be the Term Frequency (TF) or TF*IDF (Inversed Document Frequency). And then any of a number of distance measures or clustering techniques may be used to characterize the similarity of words or associate related words (ref). • syntactic relationships (shallow/deep parsing) – ??? ARE THESE KNOWLEDGE
Here we assume that specific semantic relationships relate to the grammatical
structures in which they occur and thus judging word similarity requires comparing the syntactic components and their dependency relations in the surrounding parts of each word. This suggests that we first need to extract syntactic information using at least part-of-speech tagging or shallow parsing, and then need to judge word similarity in the context of the syntactic roles that relate the extracted chunks (Grefenstette 1993; Gasperin, Gamallo et al. 2001). After that, the grammatical context of the word can be translated into a set of attributes that includes might include part of speec (POS) tags such as ADJ, NN, NNPREP, SUBJ, DOBJ. Finally, again we will use an appropriate measure to determine the similarity of two words.
Lin (Lin 1998) employed a broad-coverage parser to find the dependency triples
from the corpus, which is similar to Grefenstette’s method. He extracted nearly 56 million dependency triples from the 64 million words (??? AFTER THROWING AWAY NON-CONTENT WORDS???). Then he computed the pair-wise similarity between the nouns, verbs and adjectives/adverbs using the metrics of Jacquard, Dice, Cosine, and Hindle. He compared the automatically constructed thesaurus through this method with the entries in WordNet and Roget’s thesaurus.
4 Dongqiang Yang and David M. W. Powers A new approach
Yang and Powers (Yang and Powers 2005) propose a new model to inspect noun similarity based on the taxonomy of WordNet, and this sets the current gold standard for word similarity performance. Their algorithm performs far better than any current knowledge poor method relying on the statistical distribution of words – indeed their model has an almost 90 percent correlation with average human judgement for the 65 pairs of nouns (Rubenstein and Goodenough 1965), performs significantly better than most subjects, and agrees almost as well as different groups of humans of similar background. In this paper we put forward a totally new model of.distributional similarity and benchmark it against the data set used by Yang and Powers.
Basic procedures
Deese(Deese 1966) classifies part of speeches into syntagmatic and paradigmatic associations as discussed earlier: 1. Association responses for adverbs tend to reflect the syntagmatic relations. 2. Nouns are paradigmatic. The paradigmatic relations are not totally focused within a
superordinate, subordinate, and co-ordinate hierarchy. The similarity of nouns is still accessed through intersection of their descriptions that specify the characteristics of entities. From a psychological perspective Deese concludes that
• Nouns can be related by being grouped together.
• Nouns can be related by conceptual or physical environment.
• Nouns can be related by sharing common attributes. 3. Verbs and adjectives fall in between syntagmatic and paradigmatic associations
Clark and Card (Clark 1969; Clark and Card 1969) argue that the conceptual
relations are extracted from the syntactic structure in a sentence, which includes subject, direct object, and predicate of the sentence. Generally the syntagmatic relation provides us a clue for tracking down the meaning of the sentence after parsing the sentence and achieving the grammatical dependency.
Our task here is to find some mapping relations from the syntactic environment of
stimuli and responses, which includes nouns, verbs, adjectives, and adverbs, to their conceptual contiguity in a real world.
Proposal
“what is the context ?” In the oxford dictionary, the context is carefully defined as:
1. The weaving together of words and sentences; construction of speech, literary Wordnet vs. Distributional determination of word similarity 5 2. The connected structure of a writing or composition; a continuous text or composition with parts duly connected. 3. The connexion or coherence between the parts of a discourse. 4. The whole structure of a connected passage regarded in its bearing upon any of the parts which constitute it; the parts which immediately precede or follow any particular passage or ‘text’ and determine its meaning.
The essence of its definitions is the connection or link of the context is able to
cover some kind of meaning that can benefit understanding of whole discourse. A bag of words is a rough explanation of context, which is a random selection with too much noisy data. We assume shallow level context should be a fine-grained structure for which syntactic dependency is source. Otherwise no big difference exists between animal language and human language (Nowak, Plotkin et al. 2000).
To retireve these syntactic dependency as correct as possible we employ a wide-
used free parser based on link grammar1.
Suppose a triple < w1, r, w2> to describe objects w1, w2 and their dependency r
where r has bi-directional actions on the pair of words w1 and w2. For example if w1 modifies w2 in the kind of modification relation r, all such w2 in the corpus form a context for w1, and all w1 in the corpus will be context for w2.We cover 5 categories of relationships between words, as shown in table1:
1. action modifier (RV) : holds adverb and verb relations
E*: Adverb.+ verb, adjective, other adverb etc. MV* : verb+ all kinds of modifing-verb (Adverb, participle etc.) MV* + I, J, Mg: verb+ .+ preposition phrase, Participle (infinitival) modifiers
etc. 2. object modifier (AN) : covers adjective and noun relation
A, AN: adjective, noun + noun; M [a, g, v, p, r]: noun + all kinds of post-nominal modifier; Mp + * : noun + , + all kinds of post-nominal modifier;
3. agent to predict (SV): contain subjective noun and verb relations
4. predict to argument (VO) : contain objective noun and verb relations
O : verb + direct objects or indirect objects or infinitive complement
5. subject to object (SO) : keep track of noun to noun relations.
Table 1. an example sentence and different links in it “The care of people in the community, with are ill with HIV infection and AIDS, together with the education of schoolchildren to help prevent the spread of this terrible disease is becoming more and more urgent.” _exerted from BNC
6 Dongqiang Yang and David M. W. Powers
After extracting the relationships and morphological analysis, we construct five
raw matrixes, which can be taken as targets by contexts. For the 5 matrixes, we will handle them with same techniques in following sections. Without loss of generosity let’s denote the subject –verb matrix as Xsv. Xsv
correspond to subjects in each language segment, and columns correspond to verbs. xij is the total frequency of the ith subject with jth verb. The ith row of Xsv constructs the profile of ith subject in which it relates all different verbs in the corpus. And vice verse in the jth column of Xsa which reflect the attributes of the jth verb in the context of different subject.
Space transmission
The kernel problem is to find how translate the syntactic space or word occurrence
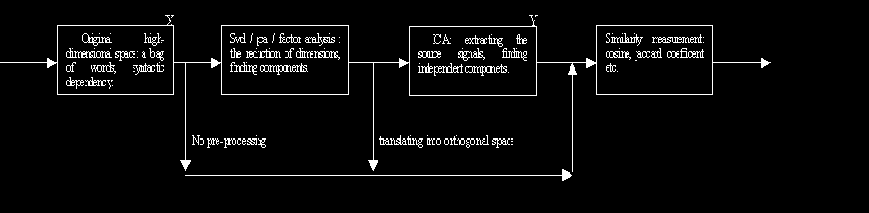
space into semantic space, i.e. how to find a suitable function to represent the meaning of words. Some researchers directly shift the syntactic space X into semantic space with complex similarity metrics like mutual information of two objects (Hindle 1990), weighted Jaccard efficient (Grefenstette 1992). (Deerwester, Dumais et al. 1990) in the latent semantic analysis (LSI) dig out concept space with single value decomposition (SVD) to solve the problem of synonyms and polysonyms trouble problems in information retrieval. (Honkela and Hyvärinen. 2004) use independent component analysis (ICA) to extract linguistic features shared by words after constructing a context space of 2000 common words.
Wordnet vs. Distributional determination of word similarity 7 Fig. 1. the architecture of space transformation.
We assume SVD can detect a kind of pseudo-semantic pattern behind the noisy syntactic representation. The following is the decomposition of XSV:
Where U is a m × r matrix of left single vectors from the standard eigenvectors of
, r is the rank of XSV (r ≤ min(m, n)), VT is a r × n matrix or
right single vectors from the eigenvectors of X T
columns of U renew the context of each subject as an eigen-verb, the rows of VT renews the context of each verb as an eigen-subject. The whole point of SVD relies on the keeping of first l largest single values and corresponding l left column eigenvector and l right row eigenvectors to maximally approach XSV. SVD filter out the redundant information and hold on the most useful information that has the maximum variance on each variable.
Eigen-verbs mainly capture the feature pattern of subjects in pseudo-semantic
space. Although we cannot fully understand the meaning of eigenvector in each single space SVD still can classify source signals with uncorrelated eigen-verbs or eigen-subjects, extract some underlying patterns from the syntactic space. If we assume the meaning of word is linear combination of eigenvectors, and matching feature sets of different words scores their proximity in the semantic space, semantic attributes, which are subject to these, are just uncorrelated but not independent owning to its ability to distinguish direction of semantic characters.
Suppose Multivariate data is distribution of gaussian, SVD/PCA (principal
component analysis which has same effect when components are outputs of covariance matrix of X) is just trying to find as faithfully as possible to represent the syntactic space with the second order information from the covariance matrix. The pseudo-semantic space is located along with orthogonal direction of eigenvectors that maximize the variance of XSV.
8 Dongqiang Yang and David M. W. Powers
ICA is a kind of high-order methods that try to find information outside the covariance matrix.
Where Y is a l × m matrix of mixed signals which in our case is from the UT or VT
of SVD of XSV. S is a l × m matrix which is recovered as source signals or latent variable from ICA. A often refers to mixing matrix that ICA need to determine. Different from second-order methods like SVD and PCA, ICA manages to find the direction of original signals to make the semantic space meaningful (Hyvärinen 1999). All of the recovered signals are independent and nearly satisfy the non-gaussian distribution otherwise the uncorrelated variables in the covariance matrix is easy to find impendence in the gaussian distribution, which is enough in task of PCA. It is worth to mention that for the source signal extracted from ICA, we cannot decide the order of signals, which are arbitrary permutation of different output.
Experiment preparation
We parse British National Corpus (BNC), which contains nearly 100 million words (both text and spoken English materials) to get our basic syntactic space. After filtering out function words and common words, these syntactic relations are stored in the 5 matrix, see table 2. We then translated frequency of data item in each matrix into information content with its logarithm after frequency plus one.
We first decompose each matrix by SVD to get its pseudo-semantic spaces for
rows and columns, and then we feed these spaces individually into FastICA2 to get its real semantic space.
Table 2. all kinds of different frequency of relations after parsing the BNC, here type is how many kinds of relations happened n times, token corresponding to how many relations happened n times.
2 http://www.cis.hut.fi/projects/ica/fastica/
Wordnet vs. Distributional determination of word similarity 9 Evaluation The significant single value.
The size of dimensionality of semantic space strongly depends on different sources of corpus and specific applications. The component of each entity denoted by vector in the semantic space corresponds to sematic features or attributes, which construct feature comparison model in human semantic memory. Some researchers employ whole components in context space to acquire word semantics (Grefenstette 1992; Lin 1997), others compress the context space to find latent semantic space, where semantic features are focused on the reduced number of components (Deerwester, Dumais et al. 1990). Even in methods facing reduced sematic space there are absent of consensus in defining how to describe feature sets. The impression of all the works grounded on SVD or PCA comes out to adjust the number of principle components to adapt distinctive applications. The best performance is subject to how many single values a system is outputting. Most language application projects employ at lest 200 principle components to describe the transmitted space and reduce the expensive computing. In the work of gene expression analysis by SVD, (Wall, Rechtsteiner et al. 2003)) only employ the first two principle components. Here our motive is not to make a big difference with other similar algorithms in some specific applications or evaluations, but to try to state that the term space of syntactic dependency can also anticipate semantic space of concepts. Henceforth we output a fixed number of the principal components as a fundamental dimensional size of pseudo semantic space before we commence each evaluation. It does not mean this number will be the optimal value for each standard evaluation, which makes the highest score in the trial. In what follows, we explain how to select the reasonable number.
In the hand –crafted semantic net, Roget’s Thesaurus -1911, there are nearly 1,000
semantic categories, which organize over 40,000 words. With respect to expensive computation of SVD on our sparse matrixes and the huge word sense pairs (approximately 200,000) in WordNet we set up 1000 as default size of semantic feature set, viz. we export 1000 single values in each syntactic matrix and then to tailor an appropriate size of dimensions.
10 Dongqiang Yang and David M. W. Powers
Generally we don’t clearly distinguish PCA and SVD on their functions of
compressing vector space. But if we are reluctant to demean X before we perform SVD we cannot state that the variances of the compressed semantic space (X’* V or equally U*S) are exactly captured by the square of single value (S). In our case of extra sparse matrix over 95 percent of entries in the matrixes is zero we can safely claim that demeaning operation has little difference on the variance of reconstructed semantic space, and the square of ordered single vales indicate the significance of single vectors, which capture the direction of maximum variance in the syntactic matrix. We decide l largest single vales by their contributions in the 1, 000 components, shown as following, p
i = si / ⊂ diag(S2) (wrong, after demeaning it goes right)
where, si is the ith single vale in S after SVD, diag(S2) is the diagonal vector of square of S.
Everitt and Dunn (2001), Wall, et al. (2003) set up a threshold, 0.7/l, where l is
equal to 1, 000 in our case, to measure the significant level of each single vale to the variance. We established 250 as a fixed size of each semantic space after checking the threshold. With the visualization of this (Figure 2) we can read that the first 2 component groups account for nearly 50 percent of variance, and after that the elbow curve turns to be smoother. We distinguish the first 250 single values that satisfy our need of the threshold, and hold nearly 76 percent of the variance in the syntactic space, as general size of semantic dimension. The other 750 single vales are cancelled, as their corresponding eigenvectors are insignificant features, as far as their rates of variances are concerned.
Wordnet vs. Distributional determination of word similarity 11 Fig. 2. visualization of significant single values (every 10 single values as a group) Some similar words
After reducing the dimensions of syntactic space, we should give some results on first 10 similar words we find after comparing all of the words in the pseudo-semantic space. Another thing is about how to evaluate the synonyms list of a target word using distributional similarity when we can't find a common benchmark set and there are absence of standard valuation to practise (some hiring subjective judgement, some using WordNet or Roget or dictionary to compute the size of intersection between the list and the synonyms or definitions of these knowledge bases).
We want to set up a fixed distance (one link or 2, 3 inks between the words in the
taxonomy of WordNet), which will limit the maximum steps between the target word and the word in the list. If we find there exists some kind of links between target word and candidate word (one of similar words to the target word) in a definite distance, we take it as a hit. Therefore, we can derive a hit ratio on a small data set, i.e. 12 words, which is employed by Yarowsky (1995)in his word sense disambiguation work.
In the same time the problem is the objectivity of the WordNet, since some
hierarchies are not well organized. For example our distributional strategy can find a similar word, vaccine, or the target, drug. But the WordNet can't find any relation between them in the distance of less than four. In other words it doesn’t mean our distributional similarity can't give the right synonyms or near synonyms of the target word. it is subjected to the correctness of WorldNet.
Table 3. the first 10 similar words of each target in the syntactic space (RAW), psudo semantic space (SVD), and semantic space (ICA)
12 Dongqiang Yang and David M. W. Powers Table 4. the related word found. Syn: synoynm; 1: only one link between the target word and all its 10 similar words. (distance is 1); 2: 2 links >3: more than 3 links. All: total links between the target word and all its 10 similar words. Wordnet vs. Distributional determination of word similarity 13 65 pairs of good enough word pairs.
To evaluate finding word association is not a relaxing task. There is no consensus on the standard for evaluation of lexical similarity. Plenty of researchers validate their word similarity metrics with human judgements on the same dataset (cf. (Yang and Powers 2005)). This dataset is from psycholinguistic test performed by Rubenstein and Goodenough (Rubenstein and Goodenough 1965), on judging synonymy of word pairs, where they hired 51 subjects, two groups of college undergraduates, to evaluate 65 pairs of nouns by assigning a similarity from 0 to 4. we still employ the dataset to access extent to what we can find a pair of words are similar.
In this task, we test 3 kinds of space: syntactic space where data entry is simply
coroccurence frequency without any other preprocessing, pseudo semantic subspace after SVD, and semantic subspace through ICA. We also list edge-counting method proposed by (Yang and Powers 2005) in their measuring word similarity using taxonomy of wordnet, which perform best in the current literature, to investigate what and how they are different. The result is shown in Table 3, which indicates that SVD (pseudo semantic space) and ICA (semantic space) has nearly same correlation with the human judgement (i.e. r = 0.695), which are both higher than syntactic dependency space.
Table 5. on the 65 pairs of words the result of different techniques, including edge-counting, syntactic dependency, SVD and ICA. Also lists the correlation with human judgement in the last row.
14 Dongqiang Yang and David M. W. Powers Wordnet vs. Distributional determination of word similarity 15
16 Dongqiang Yang and David M. W. Powers Discussion
For the 65 pairs words, ICA failed to improve scoring the similarity of words after the projecting of original syntactic space with SVD. Yang and Powers (Yang and Powers 2005) employed Wilcoxon signed-rank test as an alternative to the t-test to inspect the difference of correlation values of similarity metrics, since they score the dataset with different scale or equal-interval. Here we still repeat such significance test to analyse whether their differences in each space are significant. The one-tailed Wilcoxon sign-ranked test (at 95% of confident level) shows us that Y&D is significantly better than SYN (p = 0.002), SVD (p = 0.014) and ICA (p = 0.021). SVD and ICA are at near significant level to SYN (respectively p = 0.095 and p = 0.076).
Berland, M. and E. Charniak (1999). Finding parts in very large corpora. Proceedings
of the 37th conference on Association for Computational Linguistics, College Park, Maryland.
Caraballo, S. A. (1999). Automatic construction of a hypernym-labeled noun
hierarchy from text. Proceedings of the 37th conference on Association for Computational Linguistics.
Clark, H. H. (1969). "Linguistic processes in deductive reasoning." Psychological
Review 76: 387-404.
Clark, H. H. and S. K. Card (1969). "Role of semantics in remembering comparative
sentences." Journal of experiment psychology 82: 545-53.
Dagan, I., S. Marcus, et al. (1993). Contextual word similarity and estimation from
sparse data. Proceedings of the 31st conference on Association for Computational Linguistics, Columbus, Ohio.
Deerwester, S. C., S. T. Dumais, et al. (1990). "Indexing by Latent Semantic
Analysis." Journal of the American Society of Information Science 41(6): 391-407.
Deese, J. (1966). The structure of associations in language and thought. Baltimore,,
Wordnet vs. Distributional determination of word similarity 17
Dominic, W. (2003). A mathematical model for context and word-meaning. the 4th
international and interdisciplinary conference on modeling and using context, Stanford, California.
Everitt, B. S. and G. Dunn (2001). Applied Multivariate Data Analysis. London,
Firth, J. R., Ed. (1957). A synopsis of linguistic theory. Selected Papers of J.R. Firth
Gasperin, C., P. Gamallo, et al. (2001). Using Syntactic Contexts for Measuring Word
Similarity. Workshop on Semantic Knowledge Acquisition & Categorisation (ESSLLI 2001). Helsinki.
Grefenstette, G. (1992). Sextant: Exploring unexplored contexts for semantic
extraction from syntactic analysis. 30th annual meeting of the association for computational linguistics.
Grefenstette, G. (1992). Use of syntactic context to produce term association lists for
text retrieval. Proceedings of the 15th annual international ACM SIGIR conference on Research and development in information retrieval.
Grefenstette, G. (1993). Evaluation Techniques for Automatic Semantic Extraction:
Comparing Syntactic and Window Based Approaches. Workshop on acquisition of lexical knowledge from text columbus.
Hearst, M. A. (1992). Automatic acquisition of hyponyms from large text corpora.
Proceedings of the 14th conference on Computational linguistics.
Hindle, D. (1990). Noun classification from predicate-argument structures. 28th
Annual Meeting of the Association for Computational Linguistics.
Honkela, T. and A. Hyvärinen. (2004). Linguistic Feature Extraction using
Independent Component Analysis. Int. Joint Conf. on Neural Networks (IJCNN2004), Budapest, Hungary.
Hyvärinen, A. (1999). "Survey on Independent Component Analysis." Neural
Computing Surveys 2: 94-128.
Leacock, C., G. Towell, et al. (1996). Towards building contextual representations of
word senses using statistical models. Corpus processing for lexical acquisition, MIT Press: 97-113.
Lesk, M. (1986). Automatic sense diaambiguation using machine readable
dictionaries: how to tell a pine code from an ice cream cone. the 5th annual international conference on systems documentation, ACM Press.
Lin, D. (1997). Using syntactic dependency as a local context to resolve word sense
ambiguity. Proceedings of the 35th annual meeting of the association for computational linguistics, Madrid.
Lin, D. (1998). Automatic retrieval and clustering of similar words. proceedings of
Nowak, M. A., J. B. Plotkin, et al. (2000). "The evolution of syntactic
communication." Nature 404.
Pedersen, T., S. Banerjee, et al. (2003). Maximizing Semantic Relatedness to Perform
Pichon, R. and P. Sébillot (1998). "Automatic acquisition of meaning elements for the
creation of semantic lexicons." Information Society: 69-72.
Riloff, E. and J. Shepherd (1997). A Corpus-Based Approach for Building Semantic
18 Dongqiang Yang and David M. W. Powers
Rubenstein, H. and J. B. Goodenough (1965). "Contextual correlates of synonymy."
communications of the ACM 8(10): 627-633.
Salton, G. (1973). "Comment on "an evaluation of query expansion by the addition of
clustered terms for a document retrieval system"." Computing Reviews 14(232).
Wall, M. E., A. Rechtsteiner, et al. (2003). Singular Value Decomposition and
Principal Component Analysis. A Practical Approach to Microarray Data Analysis. D. P. Berrar, W. Dubitzky and M. Granzow, Kluwer:Norwell, MA: 91-109.
Yang, D. and D. M. W. Powers (2005). Measuring Semantic Similarity in the
Taxonomy of WordNet. Twenty-Eighth Australasian Computer Science Conference (ACSC2005), Newcastle, Australia, ACS.
Yarowsky, D. (1995). Unsupervised Word Sense Disambiguation Rivaling
Supervised Methods. the 33rd Annual Meeting of the Association for Computational Linguistics, Cambridge, MA.
Entrevistado(s): João dos Santos (73 anos) e Benedita Aparecida Messias dos Santos (56 anos)Entrevista e transcrição: Jussara Christina Reis e Séfora TognoloLocal: Bairro do Moinho, Nazaré Paulista/SP[.]: trecho removido ou não transcrito. Jussara : Qual que é o seu nome completo? João : João dos Santos Jussara : E o seu? Benedita : Benedita Jussara : Benedita. Benedita : A
Reflection and Penetration Depth of MillimeterS.I. Alekseev, O.V. Gordiienko, and M.C. Ziskin*Center for Biomedical Physics,Temple University Medical School,Millimeter (mm) wave reflectivity was used to determine murine skin permittivity. Reflection wasmeasured in anesthetized Swiss Webster and SKH1-hairless mice in the 37–74 GHz frequency range. Two skin models were tested. Model 1 was a sin
 Wordnet vs. Distributional determination of word similarity 7
Wordnet vs. Distributional determination of word similarity 7 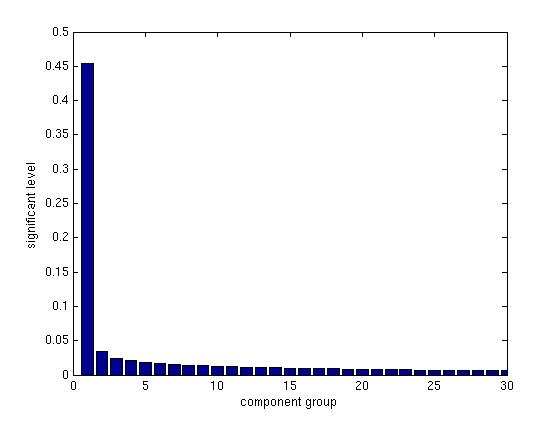 10 Dongqiang Yang and David M. W. Powers
10 Dongqiang Yang and David M. W. Powers